AI models are drowning in documents. Chroma offers a surgical solution.
The Big Picture
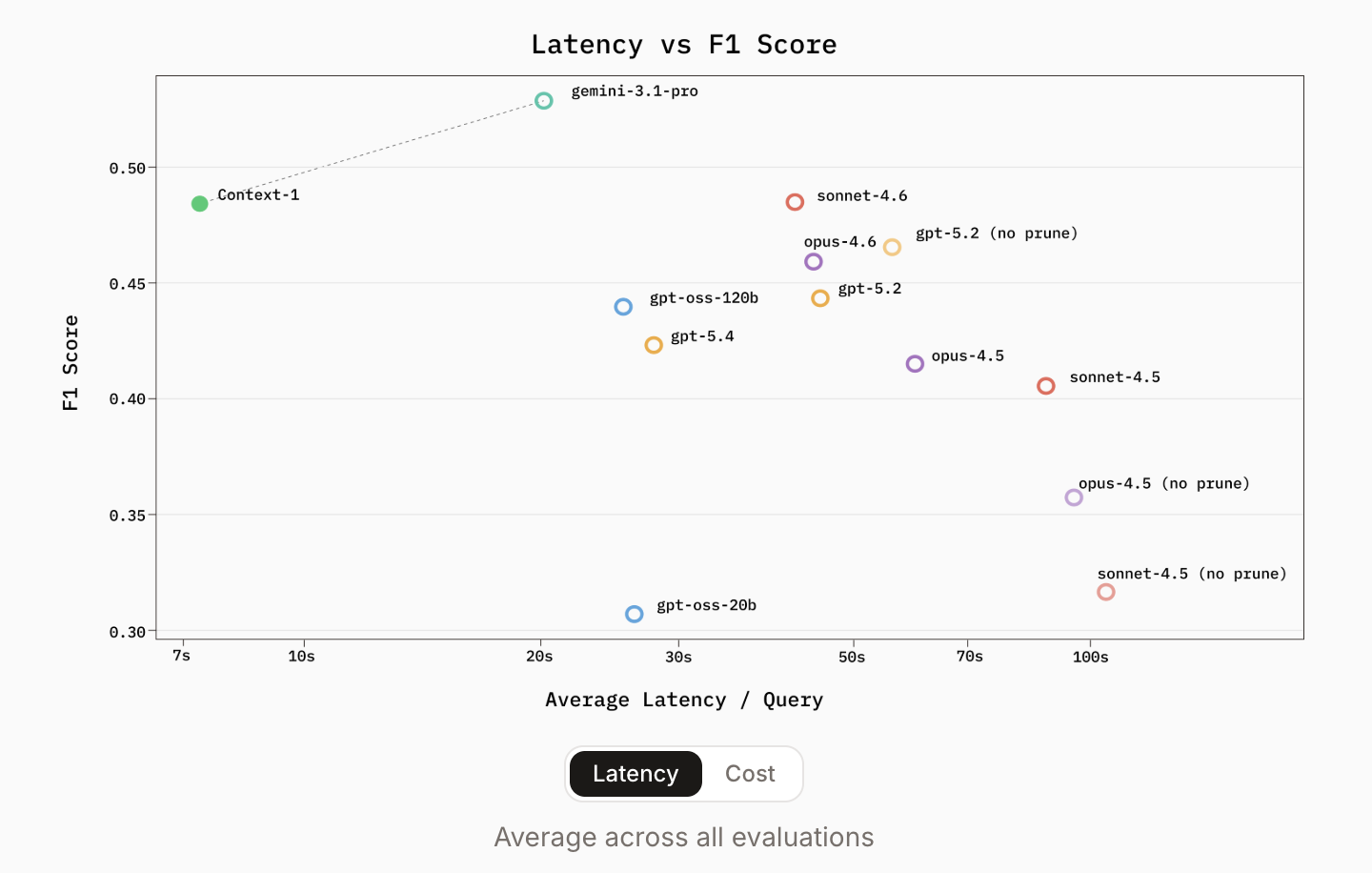
Current AI systems treat the context window like a blunt instrument. They stuff in a million tokens and hope for the best. The result: higher latency, astronomical costs, and 'lost in the middle' reasoning failures. Chroma, known for its popular open-source vector database, takes a different path. Their new Context-1 model acts as a specialized retrieval subagent. It doesn't try to be a general-purpose reasoning engine. It's an optimized scout for one task: finding the right supporting documents for complex queries and handing them off to a frontier model for the final answer.
“A 20B parameter model can now navigate SEC filings with the precision of much larger models.”
Why It Matters

The architectural shift is the most important takeaway. Context-1 decouples search from generation. In a traditional RAG pipeline, the developer manages retrieval logic. With Context-1, that responsibility shifts to the model itself. It operates inside an agent harness that lets it interact with tools like hybrid search (BM25 + dense), regex, and document reading.
The most technically significant innovation is Self-Editing Context. As an agent gathers information over multiple turns, its context window fills with documents—many redundant or irrelevant. General models eventually choke on this noise. Context-1, however, has been trained with . Mid-search, the model reviews accumulated context and proactively executes a command to discard irrelevant passages.


