Microsoft acaba de liberar tres modelos de incrustación de texto que redefinen la búsqueda multilingüe. Para desarrolladores de IA y empresas de tecnología inmobiliaria, esto marca un punto de inflexión en cómo se procesan documentos y consultas en múltiples idiomas.
El panorama general Los modelos Harrier-OSS-v1 representan un alejamiento radical de la arquitectura tradicional. Durante años, los sistemas de incrustación como BERT han dominado el panorama, utilizando codificadores bidireccionales que procesan todo el contexto simultáneamente. Microsoft optó por arquitecturas de solo decodificador, similares a las que impulsan los modelos de lenguaje grandes modernos.
Esta elección arquitectónica cambia fundamentalmente cómo se procesa el contexto. En un modelo causal, cada token solo puede atender a los tokens que lo preceden. Para crear una representación vectorial única del texto completo, Harrier utiliza "last-token pooling": toma el estado oculto del último token de la secuencia y lo normaliza L2 para garantizar magnitud consistente.
“La ventana de contexto de 32.768 tokens permite incrustar documentos completos sin fragmentación agresiva.”
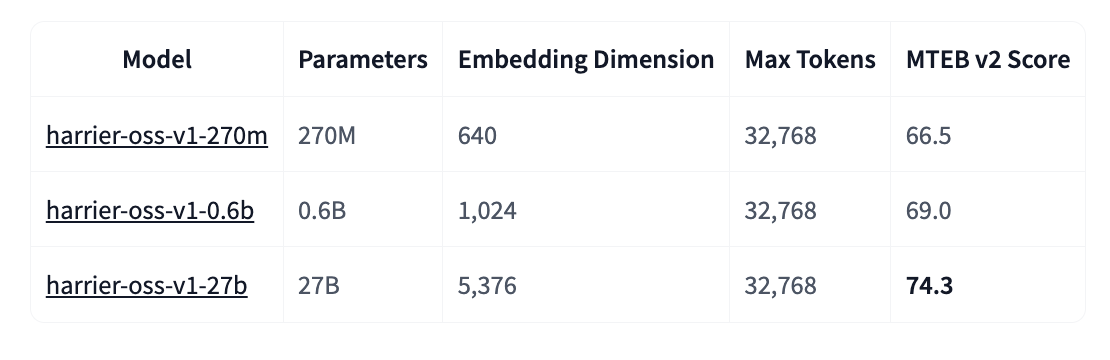
Por qué importa Para el sector inmobiliario y financiero, donde los documentos suelen ser extensos y multilingües, las especificaciones técnicas importan. **Los tres modelos ofrecen ventanas de contexto de 32.768 tokens**, un salto cuántico frente a los 512 o 1.024 tokens típicos de los modelos tradicionales. Esto significa que listados de propiedades, contratos complejos o análisis de mercado pueden procesarse como documentos completos, preservando la coherencia semántica que se pierde al fragmentar.

La implementación basada en instrucciones es igualmente crucial. Los desarrolladores deben anteponer instrucciones específicas a cada consulta: "Recuperar texto semánticamente similar" o "Encontrar traducción". Este enfoque permite que el modelo ajuste dinámicamente su espacio vectorial según la tarea, mejorando la precisión en dominios como búsqueda web o minería de textos paralelos.
El entrenamiento por destilación de conocimiento potencia los modelos más pequeños. El modelo de 270M parámetros y el de 0.6B se entrenaron adicionalmente replicando representaciones de modelos más grandes, logrando calidad superior a la esperada para su tamaño. Esto los hace viables para despliegues donde la memoria o latencia son factores críticos, como aplicaciones móviles o sistemas de búsqueda en tiempo real.


